From Tom MacWright’s blog post:
So, in summary: maybe people shy away from copilots because they’re tired of complexity, they’re tired of accelerating productivity without improving hours, they’re afraid of forgetting rote skills and basic knowledge, and they want to feel like writers, not managers.
Maybe some or none of these things are true - they’re emotional responses and gut feelings based on predictions - but they matter nonetheless.
I agree with MacWright that these things are true, and would add two other important reasons for detracting from LLM apps at work:
I am ultimately responsible for AI hallucinations
By nature, generative output is not guaranteed to be correct. The errors can be insidious. As the user/developer/writer, I am liable for the hallucinations in that output. This means two things. One, I have to be at least as familiar with a domain as the LLM “thinks” it does to competently steer the model through it. And two, my tolerance for risk (for work quality, loss of reputation, etc.) and trust in a particular model are critical factors. Why should I deal with software unpredictability when I can bridge my knowledge gaps, make my own mistakes and learn from them? This is a major question no LLM app company is interested in answering.
As chatbot developers use RAG and other strategies to produce trustworthy output, I wish they’d adopt WolframAlpha’s prompt parsing UX. This makes it easier to decide if the output is worth trusting and build a better understanding of the software limitations. It feels like Wolfram developers are humble and care about managing user expectations. Check out the screenshot below for when I ask WolframAlpha for baking directions, a topic outside of its wheelhouse.
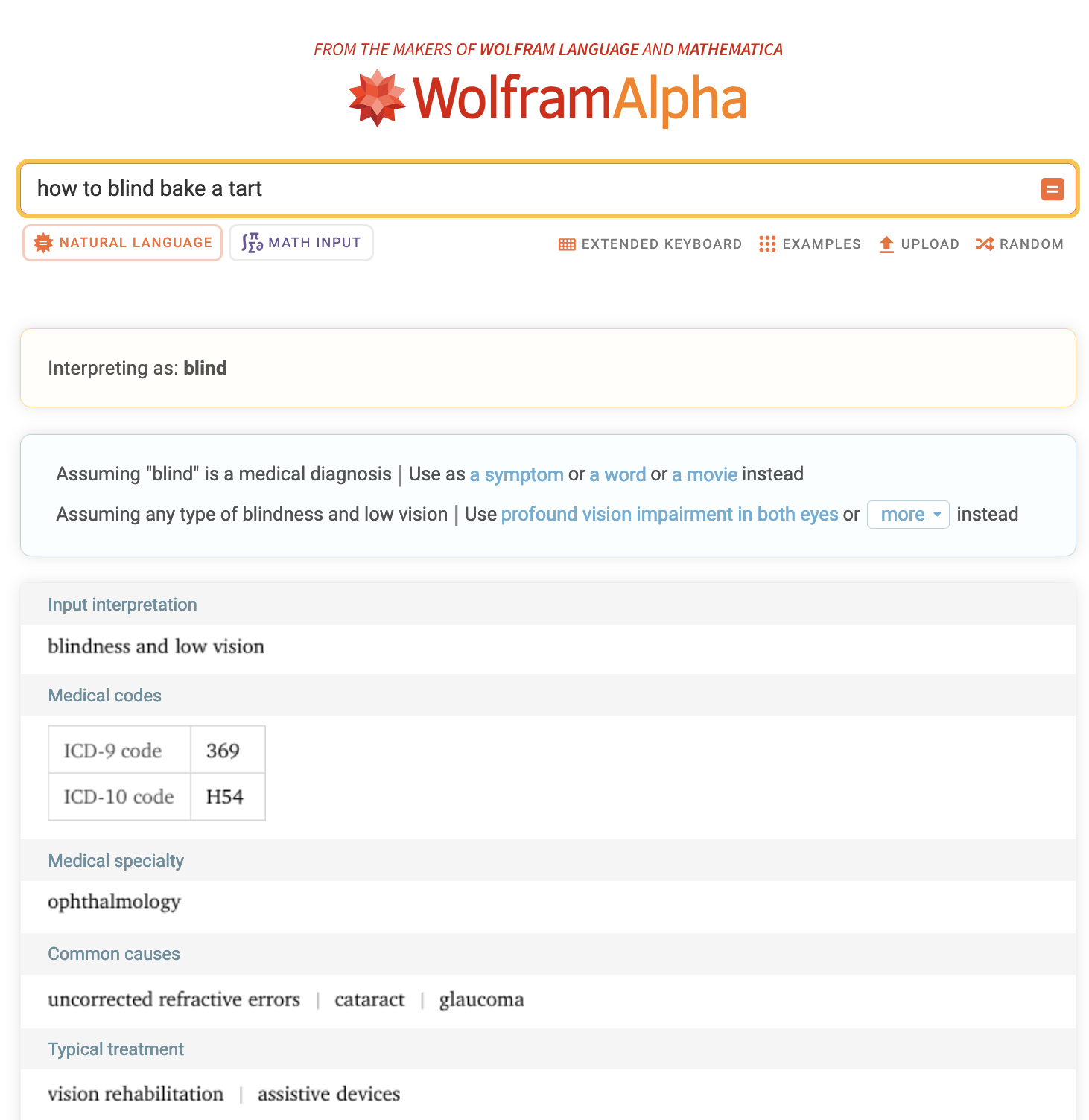
The LLM app equivalent of this UX is OpenAI o1 and other models generating chains of thoughts to respond to prompts. Sadly, this feature is also prone to hallucinations and a premium addition over the base offering.
Copilots make “good enough” the enemy of good
In programming projects, relying on LLMs lowers the bar for good design. While I write code, I am constantly refining my vision and hopefully making better design choices. But when reviewing generated code, I spend more time validating the model’s interpretation of my design rather than critically iterating on it. Maybe these are growing pains of pairing with generative AI software and I just haven’t figured out my workflow yet.
I want to trust AI enough to rely on it to work, but the current trade-offs aren’t worth the results, no matter how speedily delivered.